
在过去的几年里,Google一直忙于建设已经成为众所周知的谷歌大脑团队,并通过观看大量的视频来深度学习,直到大脑能识别什么是猫的脸,什么是人的脸。
谷歌已经雇佣很多人来增强谷歌大脑的能力,在今年前一段时间,谷歌还出重金在英国进行人才收购。如外界所传言的那样:谷歌大脑还开始直接与谷歌的搜索团队进行了深度合作。
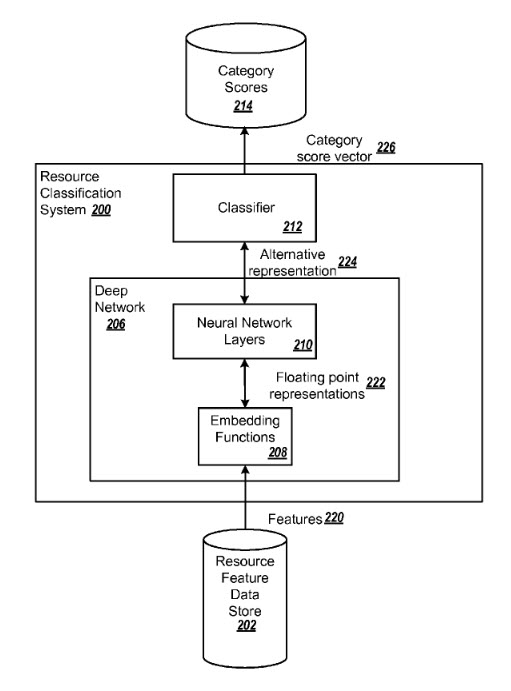
该专利描述的方法包括:
1,接收输入包含多个资源的特征,其中每个资源的特征都含有相应的属性;
2,利用嵌入函数给每一个资源特征属性赋予一个或几个数值;
3,使用一个或多个神经网络层把资源特征属性值进行处理,其中采用一个或多个非线性的转换来处理浮点值;
4,给输入的数值预先设置多个分类器,每个分类器有不同的评分方案,其中给每个类别设定上下阀值,以此阀值来判断资源该属于哪个类别。
预设的资源分类可能包含不同类别资源作弊的特征,也可能仅仅包含本类资源的作弊特征。不同类别的分数可以应用在以下几个方面:
1,来决定这个网页是否会被索引;
2,来决定这个网页是否会被展示在搜索结果页面上。
深层网络能有效地将资源分类。例如,资源可以被有效地分类为垃圾内容或者非垃圾内容。垃圾内容又可以进行细分为不同的类型,而垃圾资源则属于其中的一种或多种。专利告诉我们:
使用深层网络分类系统,可以让搜索结果能够更好地满足用户对信息的需求。比如我们可以通过检测垃圾的资源,让这些资源不展示的搜索结果中,或者让某类搜索资源只出现在这类信息的 搜索结果中。
文摘:
方法、系统和设备,包括计算机程序编码在计算机存储媒体,得分概念术语,都在使用深网络。
其中的一种的方法包括:
1,接收输入包含多个资源的特征,其中每个资源的特征都含有相应的属性;
2,利用嵌入函数给每一个资源特征属性赋予一个或几个数值;
3,使用一个或多个神经网络层把资源特征属性值进行处理,其中采用一个或多个非线性的转换来处理浮点值;
4,给输入的数值预先设置多个分类器,每个分类器有不同的评分方案,其中给每个类别设定上下阀值,以此阀值来判断资源该属于哪个类别。
专利告诉我们,这个资源资源分类系统可以让我们辨别出哪些是垃圾资源,比如:
•资源内容很垃圾;
•资源包含很多垃圾链接;
•很难判断的垃圾内容;
•诸如此类的。
一个网站上的网页其实包含很多标记化的内容,比如网址的URL、网页的标题、网站的域名、网页内容的类别、网站的年龄等。这些网页所具有的标记都会被用来计算一个网页是否是垃圾内容 ,从而确定是否对网页进行索引或降低网页关键词的排名。
例如我们对网页所代表的标记特征进行打分,然后通过生深层网络建立决策进行对网页综合评分,我们给总分设立一些阀值,如果超过一定的阀值就可以直接不对网页进行索引。
同理,我们也可以通过分类系统对网页内容进行分类,如果网页内容分类与用户搜索的分类相同,那么就可以提升这个网页的排名;而如果一个网页的分类与用户搜索的分类不相同,就可降低这个网页的排名。根据这样的处理,用户将会更加容易寻找到符合他们特定需求的内容。
但专利本身没有提供太多的处理细节和这个机器学习模型的具体功能。



